

Up-skilling, Re-skilling, Cross-skilling ….New success mantra for the IT Industry
December 23, 2020
Basic building blocks of KNIME for data analytics
May 26, 2021
Beginner’s guide for : What, Why, How

Introduction
Data Science, AI, and Machine Learning are now becoming integral parts of many industry verticals including healthcare, Fintech, retail, manufacturing, utilities, media, and many more. To develop a model in Machine Learning, one needs to understand Linear Algebra, Statistics, and other important concepts in Mathematics. Even though you are already comfortable with the subjects mentioned, you still need to learn not only ‘HOW TO CODE’ (in Python/R/Go) but also several important concepts in Computer Science like Data structure, Algorithm, and Database. Additionally, to start a project in Machine Learning, one needs to learn how to install and set up the whole coding environment, as well as how to use the command line. These issues are tedious and become one of the biggest challenges for newcomers and beginners in learning several important concepts simultaneously to get into Data Science, Data Analysis, and Machine Learning spaces. Unfortunately, some people give up and never look back to Machine Learning again.

However, good news is that there are some solutions. With great development in GUI-based applications, the introduction of KNIME is a major game-changer for non-programmers. We can call Knime a drag and drop data science tool. The major benefit of KNIME is that no programming knowledge is required. If you know how to use Microsoft Excel, KNIME gives you the same feeling. All you need to do is just get into the KNIME website and download the application and, you are ready to get into the world of KNIME without any further setups required and can start exploring the following activities.
- To load a dataset (excel, csv, file, database, etc), one needs to just drag and drop your file in!
- To clean and pre-process data, just click the functions through various preloaded nodes!
- To select, train, and test Machine Learning models, just drag and drop any model you want!
- To visualize your interesting findings, just drag and drop any kind of graph you want!
This allows you to focus your efforts on applying Machine Learning algorithms and techniques to your problems and subjects you are interested in on the first day of your work!
In summary, to use KNIME, all you need is to just simply define the Workflow between a variety of predefined nodes which are already provided in its repository. This is very convenient since KNIME already provides several predefined components called “Nodes” for numerous different tasks such as Reading data, Cleaning data, Applying ML algorithms, Visualizing data in different formats, and Analyzing results.
What is KNIME?
KNIME stands for “Konstanz Information Miner” which was developed at the University of Konstanz in Germany in early 2004. It is an Open-Source software written in Java on the Eclipse SDK platform. KNIME platform relies on pre-defined components called ‘Nodes’ for building and executing ‘Workflows’. Its core functionality is available for tasks such as machine learning, data mining, analysis, and manipulation. Additionally, the extra features and functionality are available in KNIME through various extensions and supports from numerous community support groups and vendors.
Who uses Knime?
As the chart (source: enlyft.com), KNIME is gaining popularity in several industry verticals. Computer Software (18%), Information Technology and Services (8%), and Higher Education (6%) are the largest segments.
Alteryx (Based on R, Not an open-source, License Fee and offer enterprise-grade support) and RapidMiner (limited functionality in the free version) are alternative software. Also, IBM SPSS, SAS, or FOUNDRY from Palantir offer some modeling capabilities as KNIME. We expect some active user base of the above software, will shift to KNIME in coming years, as the KNIME community continues to grow.


As per Gartner 2019 Magic Quadrant for Data Science and Machine Learning Platforms, KNIME is rated highly on a leadership scale.
Why use KNIME?
KNIME is a GUI-driven platform for data analytics. This means that knowledge of coding is not a requirement (though sometimes writing code is needed but minimal if you want to add more complexity into your workflow.) KNIME is an open-source application, meaning that it is free to use. Also, it has a growing community that is providing innovative and powerful functions. Through KNIME, it is easier to understand and deploy the whole complex processes of Machine Learning from start to finish using creating, editing, annotating, visualizing, and sharing workflows. Furthermore, it allows us to integrate data from many potential sources (files, databases, web services). It enables the performance of several essential ML-related algorithms and functions ranging from basic I/O to data manipulations, data transformations, and data mining. In summary, KNIME helps consolidate the combination of various processes into one single understandable Workflow.
Basic overview of KNIME Platform and Workflow

I). Workflow Project:
It consists of LOCAL workspaces which comprise all workspaces you have created from your the ocal machine, KNIME hub where you can connect with KNIME online server and community, and EXAMPLE workspace where you can get example projects that have already been created by the KNIME community and ready to be used.

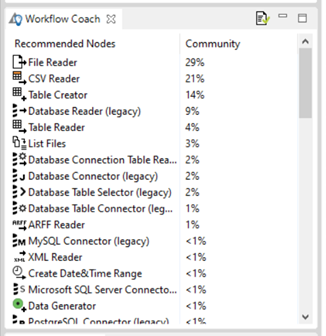
II). Recommended Nodes or Workflow Coach:
It lists nodes recommended based on the workflows built by the wide community of KNIME users.
III). Main Tab:
We can call it a ‘ToolBar’ tab as well. It consists of various basic functions for operating KNIME such as a function to execute and cancel selected nodes.

IV). Project Tabs:
It shows our current projects as you can create and execute several projects at the same time.

V). Node Repository:
It consists of all the available nodes in the core KNIME Analytics Platform and in the extensions (Also, the nodes you have installed are listed here). The nodes are nicely organized by categories based on the node functions. Under each main node category, you can expand and select specific nodes with your desired functions.
Users can also use the Search box on the top of the node repository to find specific nodes.
Each Node can have 3 states.
Red: “Not Ready/Idle” state which means that the node is not yet configured and can not be executed with its current settings.
Yellow: “Ready/Configured” state which means that the node has been set up correctly and can be executed at any time
Green: “Executed” state which means that the node has been successfully executed and we can see the results at the final nodes (downstream nodes).

VI). Node Description:
It shows the description of the currently active workflow or a selected node in the Workflow Editor or Node Repository. For a beginner, it is very useful in the initial stages of learning, who may not have a deeper knowledge of Machine Learning or forget the purposes of each node in the Workspace or in the Node Repository.

VII). Outline:
It is an overview of the currently active workflow.
it is very useful, particularly when your workflow is very big. The outline will work as a map/ big picture for your Workflow space.

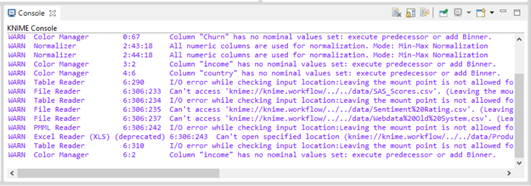
VIII). Console:
It shows the execution message and status which help indicate what is going on at the current workflow state such as successful operation, error in the file, and so on.
It is very useful in helping diagnose the workflow and examine the analytics results.
IX). Public Server:
This tab helps you connect to KNIME server in case you want to search for something on KNIME online hub.
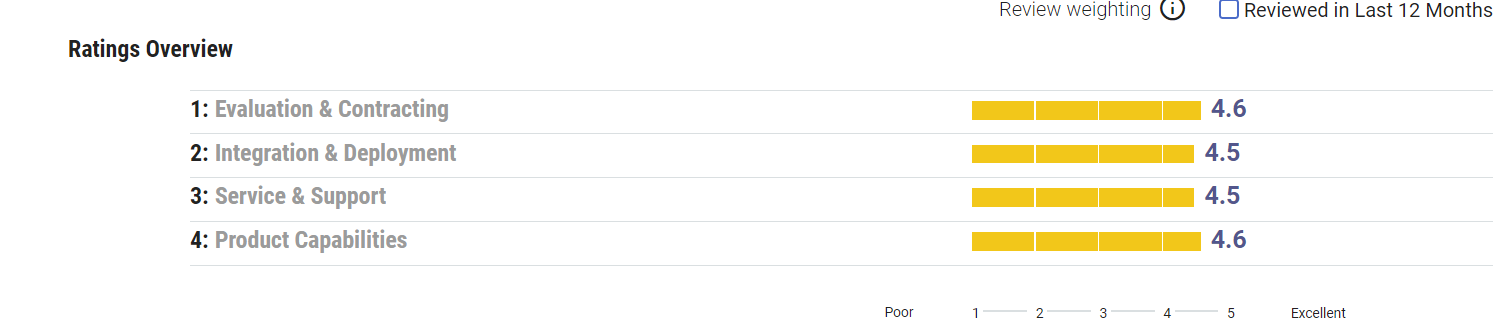
Summary:
Since its launch in 2004, KNIME has evolved a lot. As highlighted below, (Source: Gartner peer insight), KNIME is very well rated on multiple fronts.
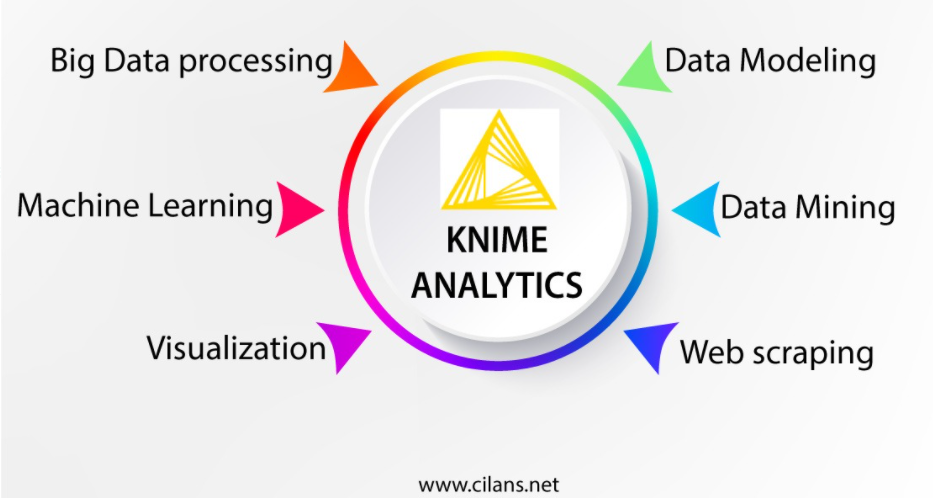
Now, KNIME is one of the most comprehensive, user-friendly, and free analytics platforms for performing machine learning, statistics, and ET tasks, as captured in the image below.
One can start the journey at the Learning page of KNIME.
Welcome to KNIME Club!
Authored by:
Team Cilans: Nikhil, Chintan, Kashyap
For additional articles on the KNIME Blog series visit www.cilans.net
Contact us at info@cilans.net for any queries.


{kind=link}
{kind=link}